,作者:新智元,原文标题:《可与H100一战,微软首款5纳米自研芯片震撼发布!Copilot引爆办公全家桶,Bing Chat改名》,题图来自:Microsoft Ignite
• 微软的AI助手Copilot进行了全面升级,包括引入自定义GPT和Bing Chat改名。
登录微软账号,就可以在Copilot专属网站上免费使用GPT-4、DALL·E 3。
而且,微软终于也开始制造定制芯片了。两款为云基础结构设计的定制芯片——Azure Maia 100和Azure Cobalt 100在昨晚闪亮登场。

除了Edge,Copilot可以在Chrome,Safari浏览器上网页运行,并且很快上线移动设备。
当然,Copilot免费版可以在必应和Windows中直接访问,还有一个专门入口()。
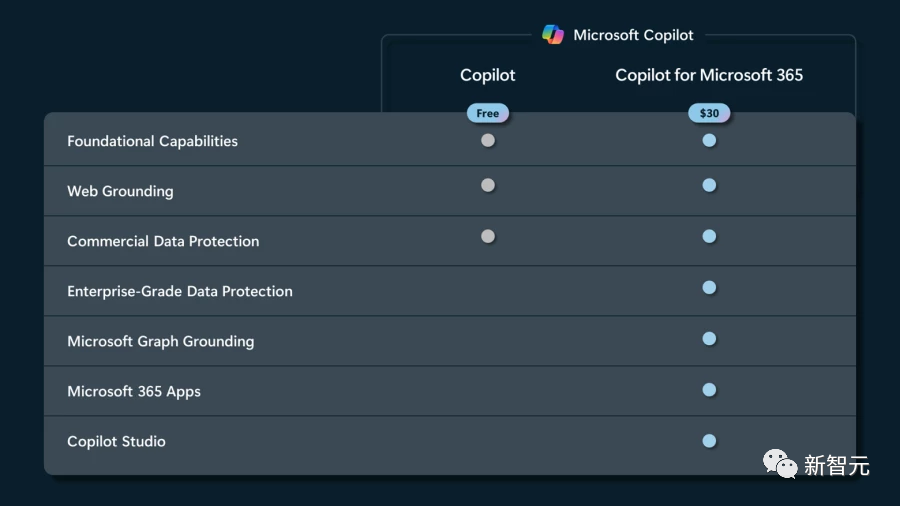
Microsoft 365的Copilot目前仅限于微软最大的客户,企业一定至少达到300个用户,才能进入AI驱动的Office助手的名单,每位用户每月收费30美元。
今年年初,微软还曾提到与谷歌搜索竞争的AI野心,但现在看起来,这家老牌巨头显然把目光投向了ChatGPT。
这不得不让外界猜想,尽管有价值数十亿美元的密切合作伙伴关系,但微软和OpenAI仍在争夺相同客户,而Copilot,就是微软试图抛给消费者和企业的最佳选择。
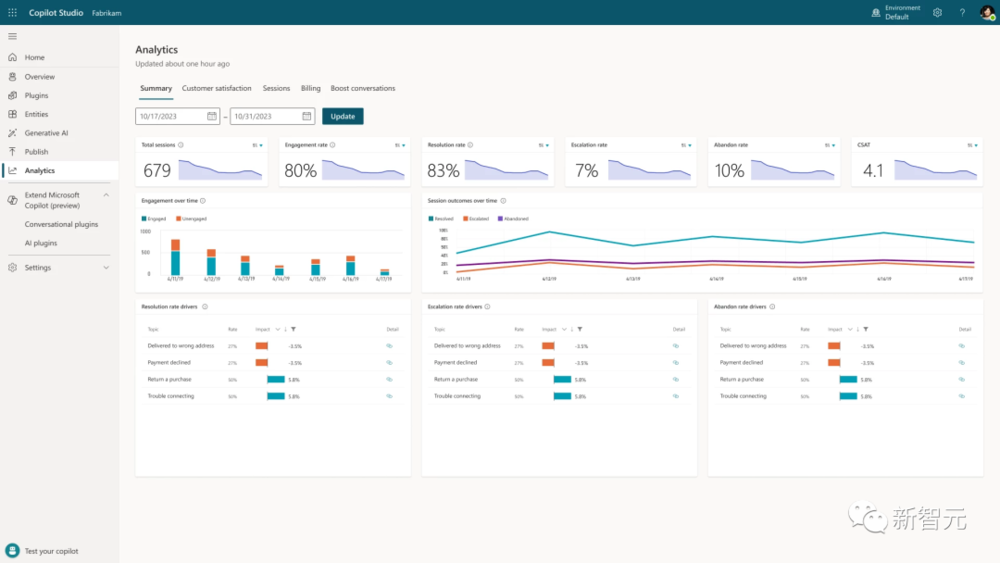
其优势在于,Copilot Studio可以在同一网页上进行构建、部署、分析、管理内容。
另外,Copilot Studio还有一个可以分析的仪表板,管理员可以集中监视使用情况并做多元化的分析,在管理中心内控制访问权限。
微软还在Dynamics 365 Guides集成了Copilot,将生成式AI与混合现实相结合,帮助一线员工完成复杂的任务。
未来,工程师无需搜索大量文档或纸质手册,仅通过自然语言和手势就能查询信息。
此前,坊间曾传出传言:微软在悄悄构建自己的芯片,用于训练大语言模型,避免对英伟达过度依赖。
今年的大模型热,让H100的需求激增,单块甚至在eBay上卖出了超过4w美元的价格。

虽然微软是四巨头(亚马逊、谷歌、Meta、微软)里最后一个发布产品的,但这次的Maia100 GPU却毫不逊色。
在算力方面能与英伟达(H100)和AMD(MI300X)一战,在网络IO方面遥遥领先,而在显存带宽方面则稍显落后。与目前使用第二代Trainium/Inferentia2芯片的亚马逊相比,纸面上的各项指标都实现了碾压。

具体来说,Maia采用的是台积电5nm节点工艺,拥有1050亿个晶体管的单片芯片。并支持微软首次实现的8位以下数据类型,即MX数据类型。
由于是在LLM热潮出现之前设计的,Maia的显存带宽只有1.6TB/s。虽然这比Trainium/Inferentia2高,但明显低于TPUv5,更加不用说H100和MI300X了。此外,微软采用的是4层HBM,而不是英伟达的6层,甚至AMD的8层。
据业内人士分析,微软当时在芯片上加载了大量的SRAM,从而帮助减少所需的显存带宽,但这似乎并不适用于现在的大语言模型。
就AMD和英伟达而言,它们都有自己的Infinity Fabric和NVLink,用于小范围芯片的高速连接(通常为8个)。如果要将数以万计的GPU连接在一起,则需要将以太网/InfiniBand的PCIe网卡外接。
对此,微软采取了完全不同的方式——每个芯片都有自己的内置RDMA以太网IO。这样,每个芯片的IO总量就达到了4.8Tbps,超过了英伟达和AMD。

为了充分的发挥出Maia的性能,微软专门打造了名为Ares的机架和集群,并首次采用了Sidekick全液冷设计。
这些机架是为Maia高度定制的,比标准的19或OCP机架更宽。
具体来说,微软在一个机架上搭载了8台服务器,其中每台服务器有4个Maia加速器,也就是共计32个Maia芯片。除此之外,还会配备网络交换机。
此外,Maia机架的功率能够达到约40KW,这比大多数仍只支持约12KW机架的传统数据中心也要大得多。
值得注意的是,微软使用的是自己从第三方获得SerDes授权,并直接向台积电提交设计,而不是依赖Broadcom或Marvell这样的后端合作伙伴。
Sam Altman表示,第一次看到微软Maia芯片的设计时,自己和同事感觉到很兴奋。而OpenAI也已经用自己的模型(GPT-3.5 Turbo)对Maia进行了改进和测试。
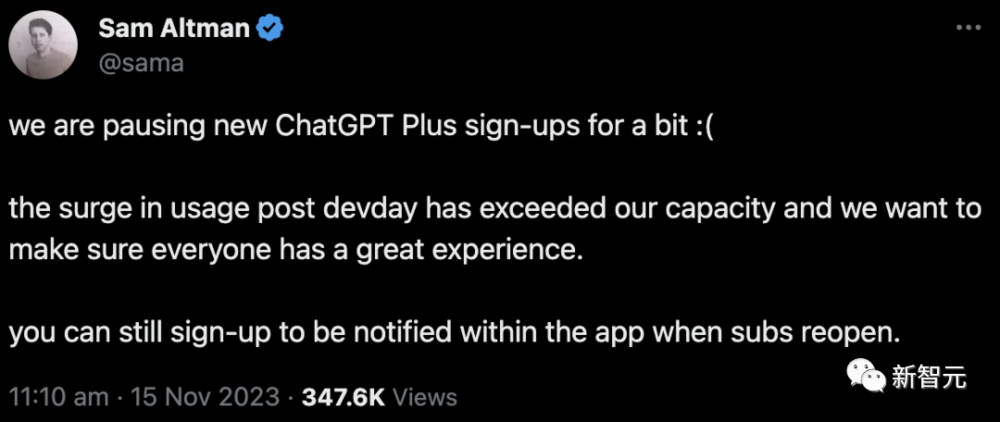
就在昨天 ,Sam Altman刚刚宣布访问量激增超出承受能力,Plus账号注册暂停
CPU方面,Microsoft Azure Cobalt是一款基于Armv9架构的云原生芯片,针对通用工作负载的性能、功率和成本效益进行了优化。

与Arm传统的只授权IP的商业模式不同,Neoverse Genesis CSS(计算子系统)平台可以使CPU的开发更快、更容易,且成本更低。
就Cobalt 100而言,微软采用的是2个Genesis计算子系统,并将它们连接成1个CPU。
Arm此前曾表示,有一个项目从启动到完成芯片只用了13个月。根据业界推测,这里提到的很可能就是微软。

可以说,微软花了许多心思。在设计上的独具匠心,不仅让它具有高性能,还能控制每个内核和每个虚拟机的性能和功耗。
目前,微软正在Microsoft Teams和SQL Server等工作负载上测试Cobalt CPU,计划明年向客户提供用在所有工作负载的虚拟机。
20多年前,微软就曾参与Xbox的芯片设计,后来还为Surface设备设计了芯片。2017年,微软就开始构建云硬件堆栈。
Azure Maia AI芯片和Azure Cobalt CPU都是在微软内部构建的,微软对整个云服务器堆栈进行了深入检修,以优化性能,功耗和成本。
用微软硬件系统负责人Rani Borkar的话说,“我们正在重新思考AI时代的云基础设施,并从字面上优化该基础设施的每一层。”
现在,微软、AMD、Arm、英特尔、Meta、英伟达和高通在内的公司,都在标准化AI模型的下一代数据格式。
Borkar回避了这样的一个问题,而是重申微软与英伟达和AMD的合作对于Azure AI云的未来很重要。“重要的是,在云运行的规模上优化和集成堆栈的每一层、最大限度地提高性能、使供应链多样化,为客户提供基础设施的选择。”
据悉,要实现ChatGPT的商业化,OpenAI需要30000块A100,如果用微软自研的芯片,显然会降低AI成本。
考虑到目前AI领域的速度,Maia 100的继任者很有可能会和H200相同的速度推出,也就是大概20个月后。
随着微软本周推出更多的Copilot功能和Bing Chat的品牌重塑,Maia必然会大显身手。
在推理方面,必须要格外注意的是,微软所做的内存权衡是非常不利的,这使得微软很难与之竞争。
H100的内存带宽是其2倍多,H200是其3倍,而MI300X甚至更高。
因此,在LLM推理方面,Maia 100的性能处于劣势。就每秒处理更大批大小的token而言,GPT-4推理的性能大约是 H100的1/3。
值得注意的是,这本身并不是一个大问题,因为制造成本与英伟达的巨大利润率弥补了大部分差距。
问题是,电源和散热仍需要更多成本,而且token到token的延迟更差。
在聊天机器人和许多协同Copliot工具等对延迟敏感的应用中,Maia无法与英伟达和AMD GPU竞争。
后两种GPU都能够正常的使用更大的批处理量,同时可接受延迟,因此它们的利用率会更高,性能TCO也比Maia高得多。
在GPT-3.5 Turbo等较小的模型中,情况要好一些,但微软不能只部署针对小模型的优化硬件。因为跟着时间的推移,GPT-3.5 Turbo等小模型将被逐步淘汰。
不仅在硬件上强强联合,微软会上还宣布将英伟达AI代工厂服务(Nvidia AI Foundry)引入Azure。
不仅有英伟达的基础模型、NeMo框架、DGX Cloud AI超算以及服务全部集成到微软Azure平台,向企业和开发者开放。

开发者方面,微软在自家的Azure AI上提供了从数十亿到数万亿不等的基础模型。
纳德拉现场激动地表示,OpenAI团队做了很出色的工作推动AI的前进,我们将继续推进深度合作。

另外,微软还将提供GPT-4的微调功能。这样,开发的人能调用自己的数据去微调自定义的GPT-4。

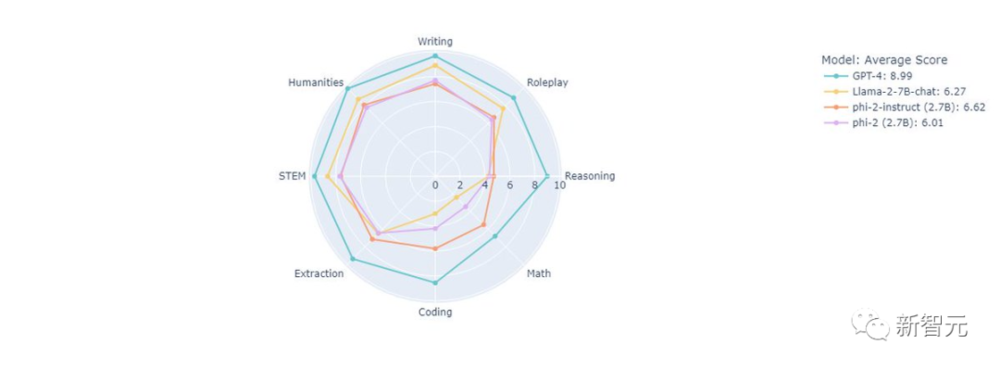
另外,微软还宣布了全新的小体量模型——Phi-2,仅有27亿参数,并将在未来开源。
最新Phi-2模型,同样是在教科书级数据上完成训练,比前身Phi-1.5更强大,在数学推理上的性能飙升50%。
除了模型,为了逐步降低开发者门槛,微软还推出了全链条开发工具——Azure AI Studio。
它提供了完整周期的工具链,是一个端到端的平台,包括模型的开发、训练、评估、部署、定制等等。